Efficient handling of invalid simulation outputs¶
For many simulators, the output of the simulator can be ill-defined or it can have non-sensical values. For example, in neuroscience models, if a specific parameter set does not produce a spike, features such as the spike shape can not be computed. When using sbi, such simulations that have NaN or inf in their output are discarded during neural network training. This can lead to inefficetive use of simulation budget: we carry out many simulations, but a potentially large fraction of them is discarded.
In this tutorial, we show how we can use sbi to learn regions in parameter space that produce valid simulation outputs, and thereby improve the sampling efficiency. The key idea of the method is to use a classifier to distinguish parameters that lead to valid simulations from regions that lead to invalid simulations. After we have obtained the region in parameter space that produes valid simulation outputs, we train the deep neural density estimator used in SNPE. The method was originally proposed in Lueckmann, Goncalves et al. 2017 and later used in Deistler et al. 2021.
Main syntax¶
from sbi.inference import SNPE
from sbi.utils import RestrictionEstimator
restriction_estimator = RestrictionEstimator(prior=prior)
proposals = [prior]
for r in range(num_rounds):
theta, x = simulate_for_sbi(simulator, proposals[-1], 1000)
restriction_estimator.append_simulations(theta, x)
if (
r < num_rounds - 1
): # training not needed in last round because classifier will not be used anymore.
classifier = restriction_estimator.train()
proposals.append(restriction_estimator.restrict_prior())
all_theta, all_x, _ = restriction_estimator.get_simulations()
inference = SNPE(prior=prior)
density_estimator = inference.append_simulations(all_theta, all_x).train()
posterior = inference.build_posterior()
Further explanation in a toy example¶
import torch
from sbi.analysis import pairplot
from sbi.inference import SNPE, simulate_for_sbi
from sbi.utils import BoxUniform, RestrictionEstimator
_ = torch.manual_seed(2)
We will define a simulator with two parameters and two simulation outputs. The simulator produces NaN whenever the first parameter is below 0.0. If it is above 0.0 the simulator simply perturbs the parameter set with Gaussian noise:
def simulator(theta):
perturbed_theta = theta + 0.5 * torch.randn(2)
perturbed_theta[theta[:, 0] < 0.0] = torch.as_tensor([float("nan"), float("nan")])
return perturbed_theta
The prior is a uniform distribution in [-2, 2]:
prior = BoxUniform(-2 * torch.ones(2), 2 * torch.ones(2))
We then begin by drawing samples from the prior and simulating them. Looking at the simulation outputs, half of them contain NaN:
theta, x = simulate_for_sbi(simulator, prior, 1000)
print("Simulation outputs: ", x)
Running 1000 simulations.: 0%| | 0/1000 [00:00<?, ?it/s]
Simulation outputs: tensor([[ 0.0538, -0.1295],
[ 0.7811, -0.1608],
[ 0.8663, 0.3622],
...,
[ nan, nan],
[ nan, nan],
[ 1.7638, 0.1825]])
The simulations that contain NaN are wasted, and we want to learn to “restrict” the prior such that it produces only valid simulation outputs. To do so, we set up the RestrictionEstimator:
restriction_estimator = RestrictionEstimator(prior=prior)
The RestrictionEstimator trains a classifier to distinguish parameters that lead to valid simulation outputs from parameters that lead to invalid simulation outputs
restriction_estimator.append_simulations(theta, x)
classifier = restriction_estimator.train()
Training neural network. Epochs trained: 46
We can inspect the restricted_prior, i.e. the parameters that the classifier believes will lead to valid simulation outputs, with:
restricted_prior = restriction_estimator.restrict_prior()
samples = restricted_prior.sample((10_000,))
_ = pairplot(samples, limits=[[-2, 2], [-2, 2]], fig_size=(4, 4))
The `RestrictedPrior` rejected 51.3%
of prior samples. You will get a speed-up of
105.2%.
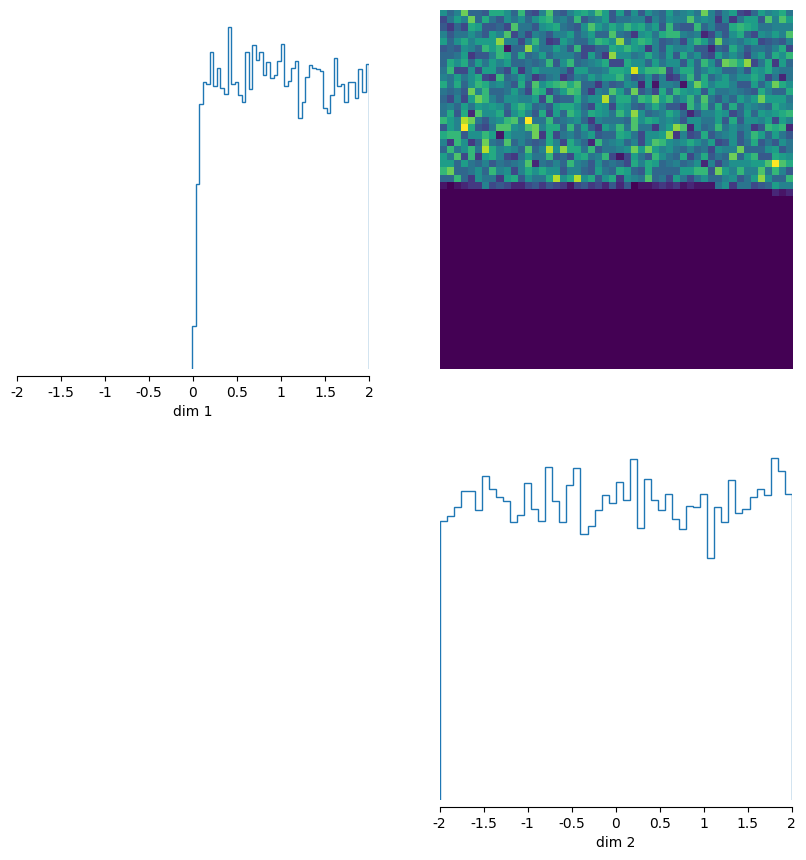
Indeed, parameter sets sampled from the restricted_prior always have a first parameter larger than 0.0. These are the ones that produce valid simulation outputs (see our definition of the simulator above). We can then use the restricted_prior to generate more simulations. Almost all of them will have valid simulation outputs:
new_theta, new_x = simulate_for_sbi(simulator, restricted_prior, 1000)
print("Simulation outputs: ", new_x)
The `RestrictedPrior` rejected 50.2%
of prior samples. You will get a speed-up of
100.8%.
Running 1000 simulations.: 0%| | 0/1000 [00:00<?, ?it/s]
Simulation outputs: tensor([[ 1.0285, 1.2620],
[ 1.5197, 1.1854],
[ 0.6391, 2.6417],
...,
[ 1.3871, -0.8298],
[ 0.9003, -1.7289],
[ 0.7951, 0.2624]])
We can now use all simulations and run SNPE as always:
restriction_estimator.append_simulations(
new_theta, new_x
) # Gather the new simulations in the `restriction_estimator`.
(
all_theta,
all_x,
_,
) = restriction_estimator.get_simulations() # Get all simulations run so far.
inference = SNPE(prior=prior)
density_estimator = inference.append_simulations(all_theta, all_x).train()
posterior = inference.build_posterior()
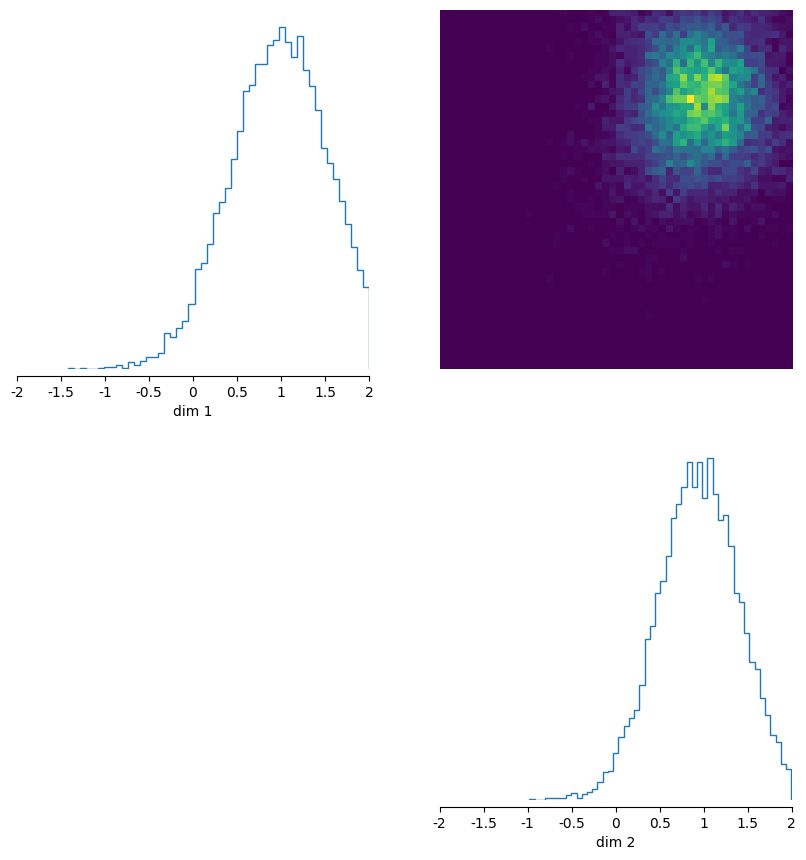
posterior_samples = posterior.sample((10_000,), x=torch.ones(2))
_ = pairplot(posterior_samples, limits=[[-2, 2], [-2, 2]], fig_size=(3, 3))
WARNING:root:Found 524 NaN simulations and 0 Inf simulations. They will be excluded from training.
Neural network successfully converged after 107 epochs.
Drawing 10000 posterior samples: 0%| | 0/10000 [00:00<?, ?it/s]
Further options for tuning the algorithm¶
- the whole procedure can be repeated many times (see the loop shown in “Main syntax” in this tutorial)
- the classifier is trained to be relatively conservative, i.e. it will try to be very sure that a specific parameter set can indeed not produce
validsimulation outputs. If you are ok with the restricted prior potentially ignoring a small fraction of parameter sets that might have producedvaliddata, you can userestriction_estimator.restrict_prior(allowed_false_negatives=...). The argumentallowed_false_negativessets the fraction of potentially ignored parameter sets. A higher value will lead to morevalidsimulations. - By default, the algorithm considers simulations that have at least one
NaNofinfasinvalid. You can specify custom criterions withRestrictionEstimator(decision_criterion=...)